Introduction
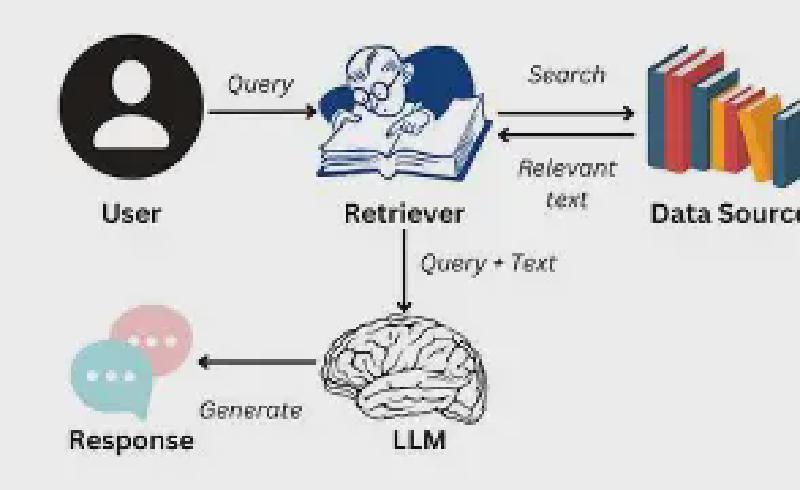
What is RAG
RAG(Retrieval Augment Generate)就是一种最优化LLMs的输出的一个方法,让大模型可以基于指定的语料库来进行生成。
Why RAG
LLMs虽然拥有庞大的训练数据,但当我们向其提问时,可能遇到以下几个问题:
- 对于常见的、开放性问题,LLMs的回答依赖于公开数据,有时虽能给出不错的答案,但也容易输出“幻觉”——即给出看似合理但实际并不存在的信息。
- 对于专业性强或企业内部的数据,比如公司政策、产品细节、历史故障记录等,传统的LLMs很难给出准确解答,因为这些内容往往没有包含在训练语料里。
RAG(Retrieval Augmented Generation)正好可以解决这个问题:通过检索公司内部文档、知识库等专有数据,把相关内容作为上下文补充到大模型前,使其结合最新、最相关的信息生成答案。这样既可以降低幻觉,提升回答的专业性和准确性,还能让LLMs灵活适应各种业务场景。这就是为什么需要用RAG来增强LLMs的理由。
基础RAG的缺陷
基础的RAG主要流程是“检索-拼接-生成”,虽然可以借助外部知识提升答案的相关性,但在实际应用中仍存在以下几个问题:
-
简单的检索策略
多数基础RAG只使用向量检索,匹配文本内容的语义相似度。但检索模型容易受限于召回率和精度,导致检索到的内容不一定是真正相关、最重要的信息。 -
检索粒度问题
通常按段落、句子或者文档进行检索,检索粒度过粗会导致噪声上下文被引入,太细又可能丢失整体语义,从而影响生成质量。 -
固定上下文窗口
由于LLM的输入有长度上限,检索到的内容超出窗口时需要裁剪或截断,这容易丢失关键信息,也限制了大模型对多条复杂知识的融合能力。 -
缺乏上下文理解和重排
基础RAG一般没有进行二次筛选或重排,LLM只能被动接受检索内容,对上下文片段之间的关系和时序理解有限,可能导致生成答案时断章取义或者语义割裂。 -
不处理检索噪声和错误
若检索误召回了无关或错误的内容,基础RAG难以自动校正,容易把误导或错误信息直接带入生成,降低安全性与可靠性。
因此,如果只是用最基础的RAG流程,很容易遇到“检索不到位、上下文无关、生成不准确”等尴尬,不能满足高质量AI问答或助手场景的需求,后续需要对RAG模块进行优化和增强。
Make a Smart RAG
多模态检索
多模态检索指的是让RAG系统能够检索并处理文本、图片、表格等多种不同类型的数据,而不仅仅局限于纯文本。这样能够更全面地覆盖各种异构信息源,在实际应用中显著提升系统的知识获取能力。例如,在法律、医疗等领域,图片、表格同样是重要的知识载体,多模态检索让RAG应对真实场景更加得心应手。
检索模型升级
检索模型的选择直接影响相关文档的召回质量。通过引入更强大的语义检索模型(比如ColBERT、Hybrid检索),同时结合关键词检索与向量检索,实现多路召回,可以大大提升检索的精准性和全面性。这为后续生成提供了更优质、更相关的上下文基础。
段落/片段智能切分
智能分割文档内容是基础且关键的一步。利用知识分块、SBD算法等工具,将长文档合理切分为粒度合适的上下文片段,可有效避免信息噪声和表达割裂。同时,良好的切分粒度确保片段包含完整的语义,提升检索和生成阶段的质量。
二次筛选与重排序
检索得到的内容往往存在相关性高低不同的问题。通过对初步检索结果进行二次打分、语义重排序(Rerank),可以结合文本语义、上下文连续性等更多维度,对召回片段进行优化排序,确保最终输入LLM的是最重要、最相关的信息段落,提高生成结果的专业性与准确性。
上下文窗口优化
LLMs具有输入窗口长度的限制,原始检索内容往往超长。通过知识压缩、摘要融合、重要性排序等方式,可以最大程度保留核心信息,在有限窗口内传递尽可能多的有用知识,规避信息丢失,提升复杂问答场景下的系统表现。
证据验证与降噪
检索内容可能掺杂错误、不相关或过时的信息。通过让LLM参与对片段的筛查、事实核验,可以自动过滤掉无关、虚假的内容,有效降低生成中“幻觉”的概率,提升最终答案的准确性和可信度。
自适应召回策略
不同的业务需求和问题复杂度对检索数量和内容长度要求不一致。自适应召回策略能够根据具体任务动态调整召回文档的数量及片段长度,在保证信息覆盖的同时,兼顾高精度和省资源,实现更智能、更灵活的上下文选取。
多轮检索和生成结合
面对连续对话、复杂需求场景,仅依赖单轮检索往往不足。多轮检索与生成结合的优化方法,可以在多轮对话中连续累积历史信息,动态调整检索和上下文输入,保证生成内容的上下文连贯,以及针对性的知识补充。
领域知识增强
在专业场景(如医疗、金融等)下,需要更专业的知识支撑。通过训练和微调领域专用的检索模型,使其对专业词汇、知识点具有更敏锐的识别和检索能力,可以极大提升RAG在垂直领域的精准召回和知识覆盖。
高质量数据和知识库建设
RAG系统的可靠性和覆盖性基础在于数据。通过定期清洗知识库、去除冗余和错误文档,并持续建设结构化、高可信度的知识底座,可以保障后续检索的高质量,同时为RAG系统的持续优化提供坚实支撑。
How to Evaluate Your RAG
RAG性能评估方法
RAG系统开发完成后,评估其效果同样重要。科学的评测不仅能检验现有方案的优劣,也指导持续的系统优化。下面介绍常见的RAG评估思路、标准和实践。
1. 检索阶段评估
- 召回率(Recall)与准确率(Precision)
测测检索出的结果中包含多少真实相关内容(召回率),以及检索结果中有多少是与需求真正相关的(准确率)。 - Top-K准确率
通常统计检索返回的前K个片段中是否包含正确答案或高相关内容,典型指标如Top-1/Top-3/Top-5 Recall。 - 覆盖率
检查知识库中与问题相关的信息是否有被检出,衡量知识库完整性和检索能力。 - 多样性
分析检索到的片段类型、来源是否丰富,评估系统面对复杂问题时的信息广度。
2. 生成阶段评估
- 答案相关性/正确率
让领域标注人员或专家判断生成答案是否覆盖关键信息、是否正确。 - 信息完整性与信噪比
检验生成内容中包含多少有用信息,是否有无关赘述或错误"幻觉"。 - 可读性与连贯性
评估输出流畅度、逻辑性,是否便于理解和采纳。
3. 端到端整体评估
- 人工标注打分
制定标准问答集,对系统自动生成的答案进行主观标注打分,如相关性、完整性、信任度等。 - 自动化评测指标
如ROUGE、BLEU等自动评分指标,适用于答案为结构化文本或标准答案较明确场景。 - 用户反馈/在线A/B测试
在实际业务流中观察用户满意度、交互点击率、辅助决策效果等真实指标。 - 事实一致性验证
检查LLM生成内容是否与检索证据保持一致,评估“幻觉”率。
4. 评测集构建建议
- 准备覆盖多业务场景、多问题类型的高质量问答对,明确标注标准答案及相关知识片段;
- 定期扩充和维护评测集,跟进业务变化和知识库更新;
- 引入专家复审机制,确保评测结论具有权威性和参考价值。
RAG系统的评估是多维度、系统化的工程。只有持续、科学评测,才能有效指导RAG的优化,实现高质量、可信赖的问答或知识助理服务。